Visualization & Analysis
EstroGene DataBase
A Comprehensive
NGS Database Focusing on Estrogen
Biology in Breast Cancer

The EstroGene Project was launched by the Drs. Steffi Oesterreich and Adrian Lee’s Laboratory at University of Pittsburgh, UPMC Hillman Cancer Center. It aims to document and integrate the majority of publicly available estrogen-related next generation sequencing data sets (including RNA-seq, microarray, ChIP-seq, ATAC-seq, DNase-seq, ChIA-PET, Hi-C, GRO-seq, etc), and establish a comprehensive data base to allow users’ customized data search and visualization visualization.
Estrogen receptors (ER) belongs to the nuclear receptor family which is indispensable for sensing estrogen signaling and mediating development, metabolism, homeostasis and other essential functions of the organism. ER-α has been widely reported as the key estrogen signaling receptor in ER+ breast cancer, which accounts for above 70% of all breast cancer cases. Upon activation by ligands, ER-α tends to form dimers and binds to genomic DNA to trigger the confound downstream effects. The rapid development of next generation sequencing technologies leads to hundreds of unbiased genomic profiling and benefits a comprehensive understanding of estrogen receptor actions in breast cancer. However, lack of a central database which curates and summarizes these publicly available estrogen data sets largely limits the power for these NGS profiles.
It is a comprehensive database:
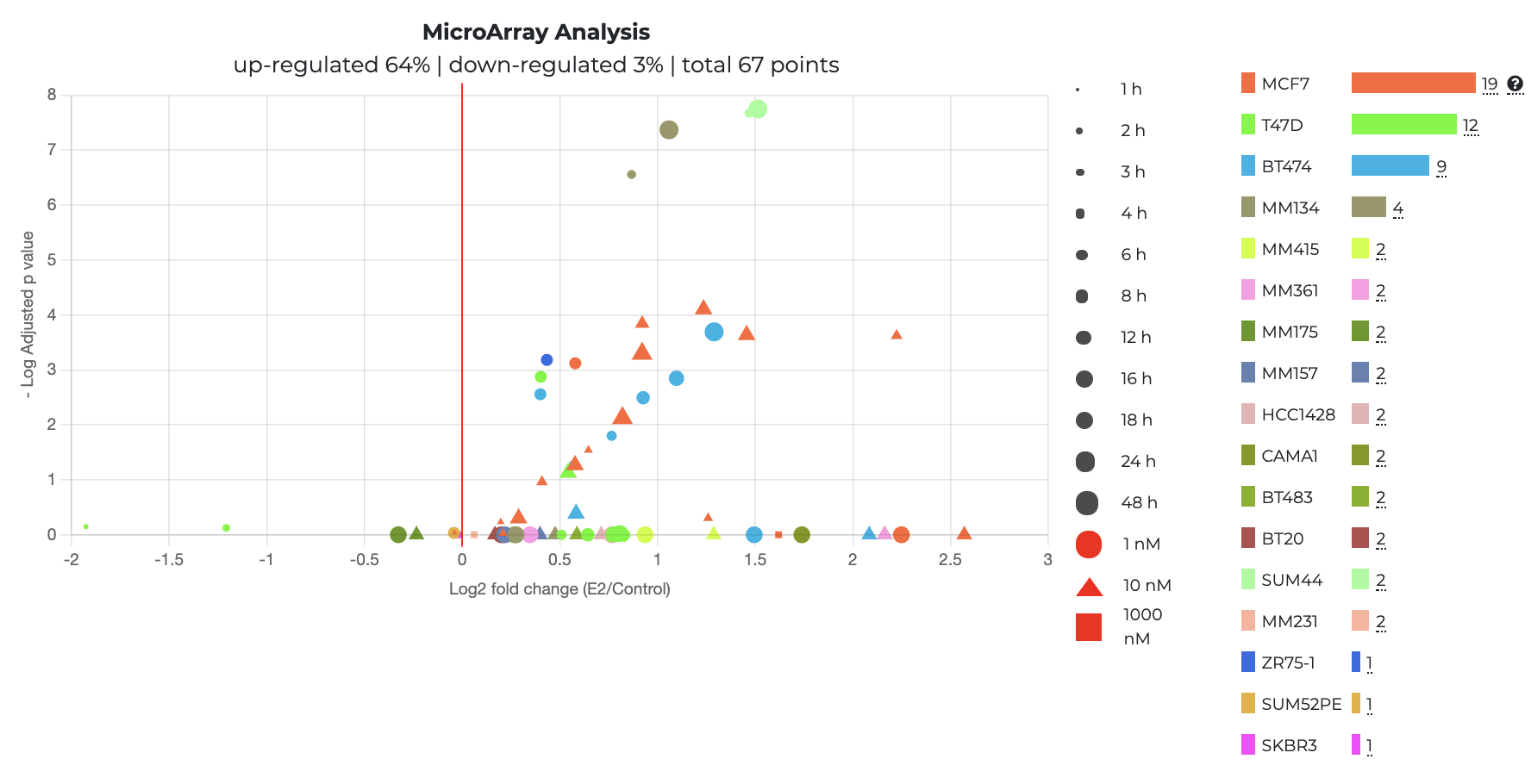
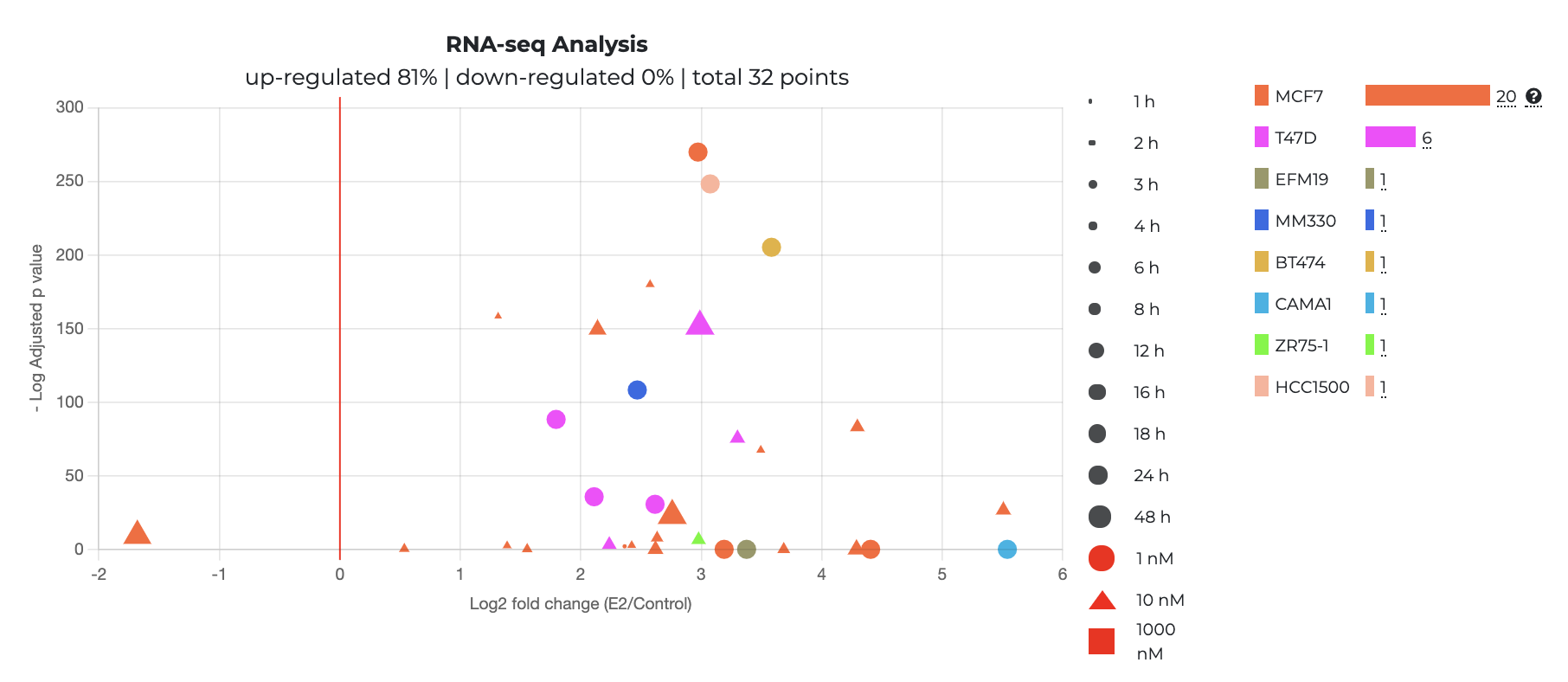
Transcriptomic Analysis (microarray and RNA-seq):
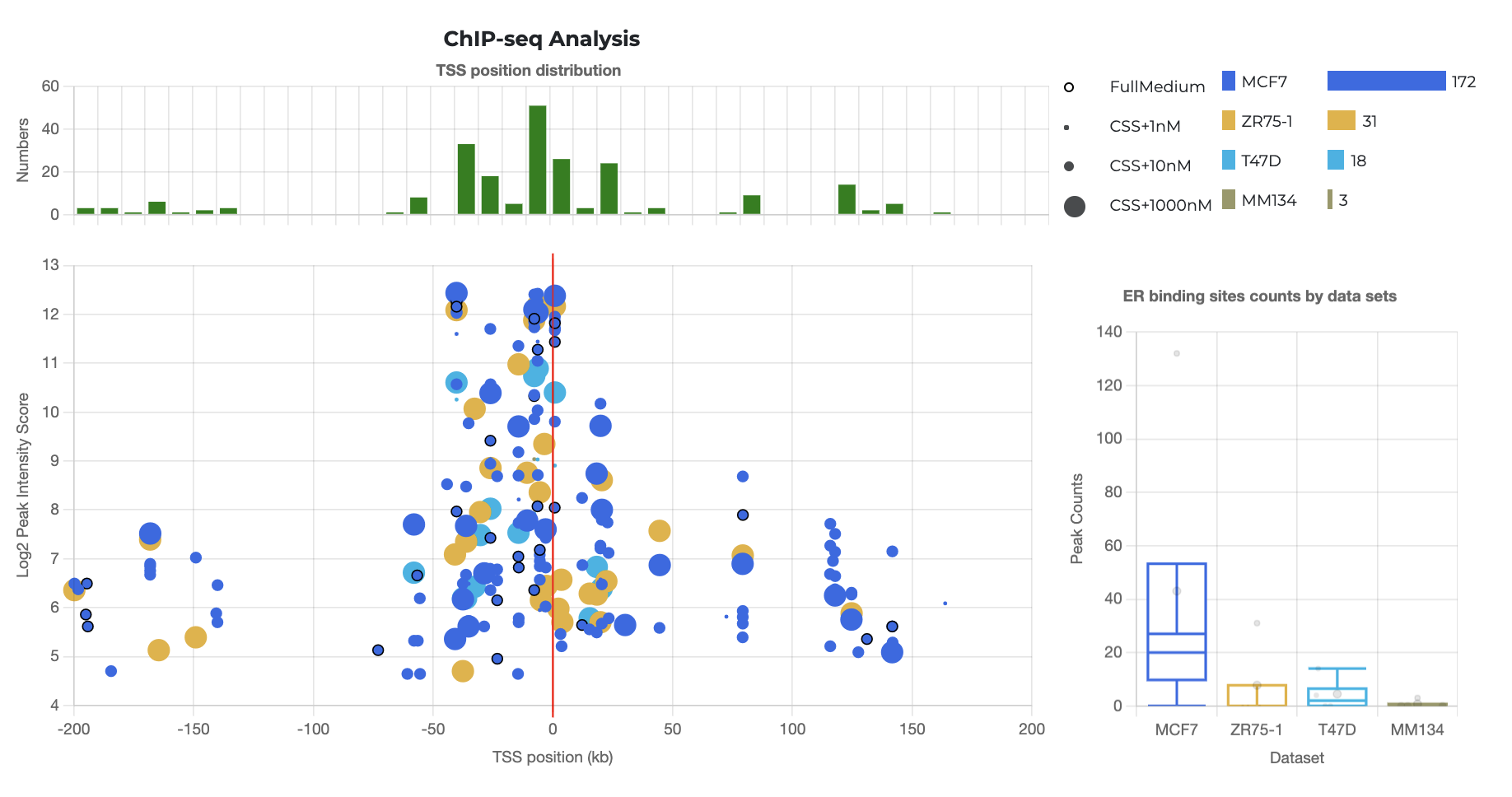
ER Cistromic Analysis (ChIP-seq):
Gene query with users-defined conditions:
Continuous crowd-sourcing from the scientific research community: