EstroGene MetaData
Documentation about the dataset we include in our project for analysis
Metadata inventory of all the curated data sets can be access via this google form link.
We kindly ask the users not to edit the existing contents. Any suggestions for new data sets to be included can be added in the last spreadsheet of this google sheet following the format we created. We will update the database accordingly.
Dataset Components
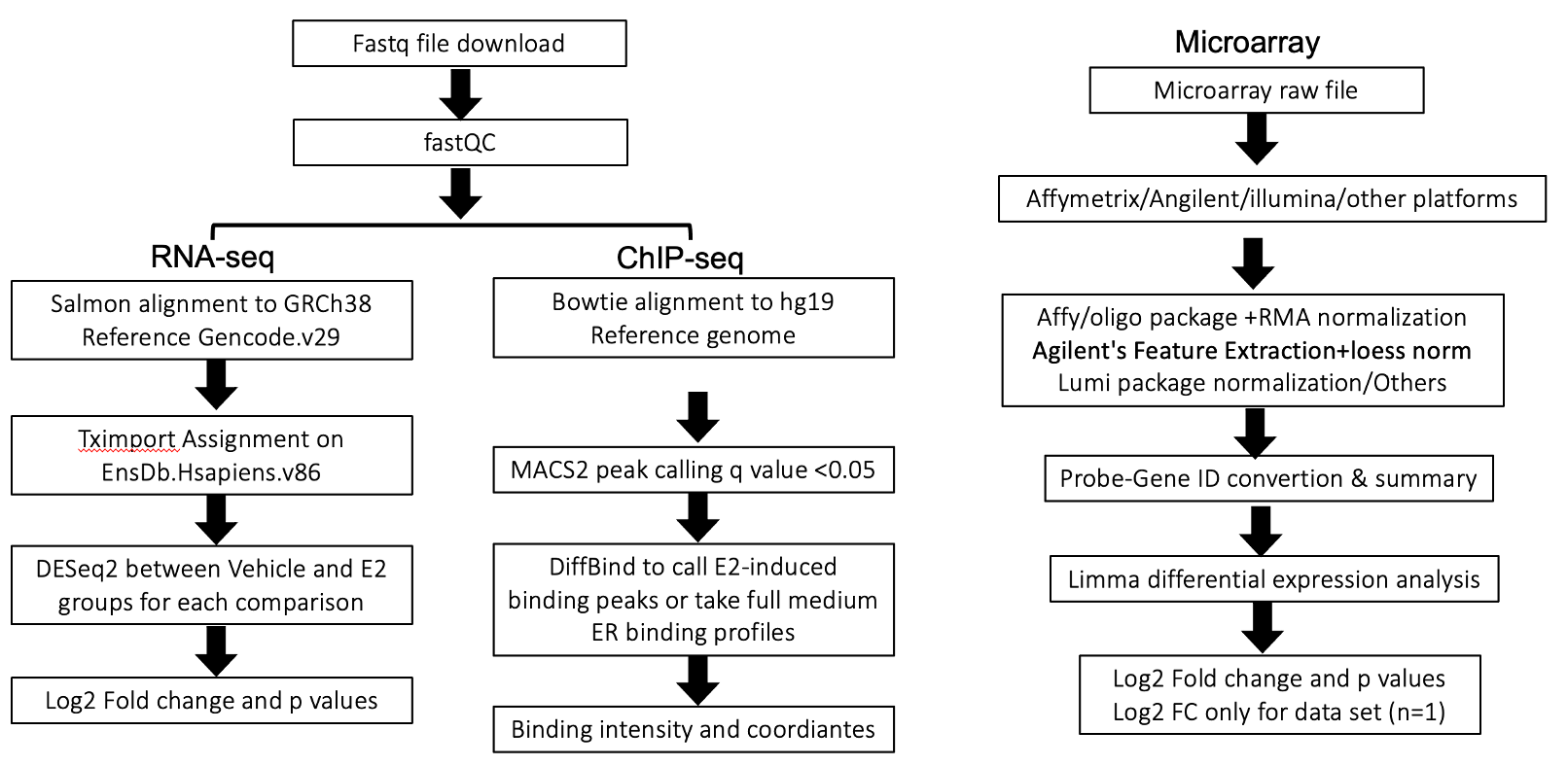
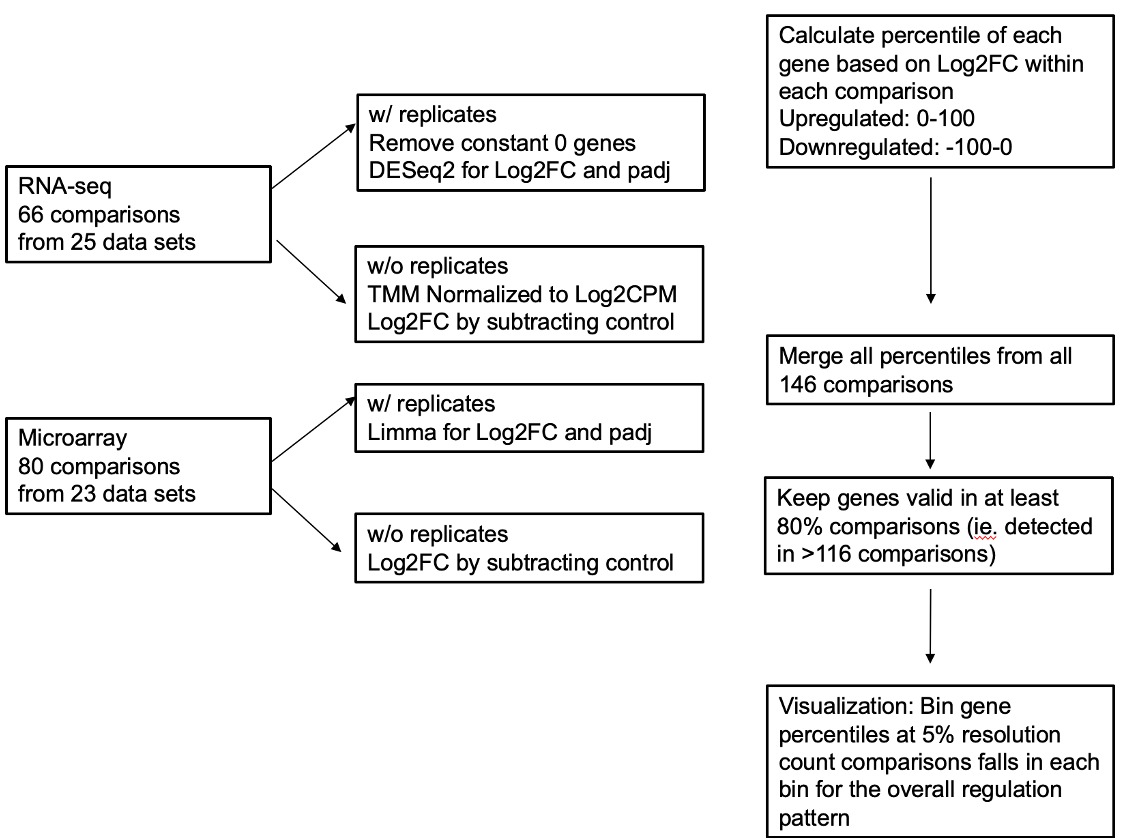
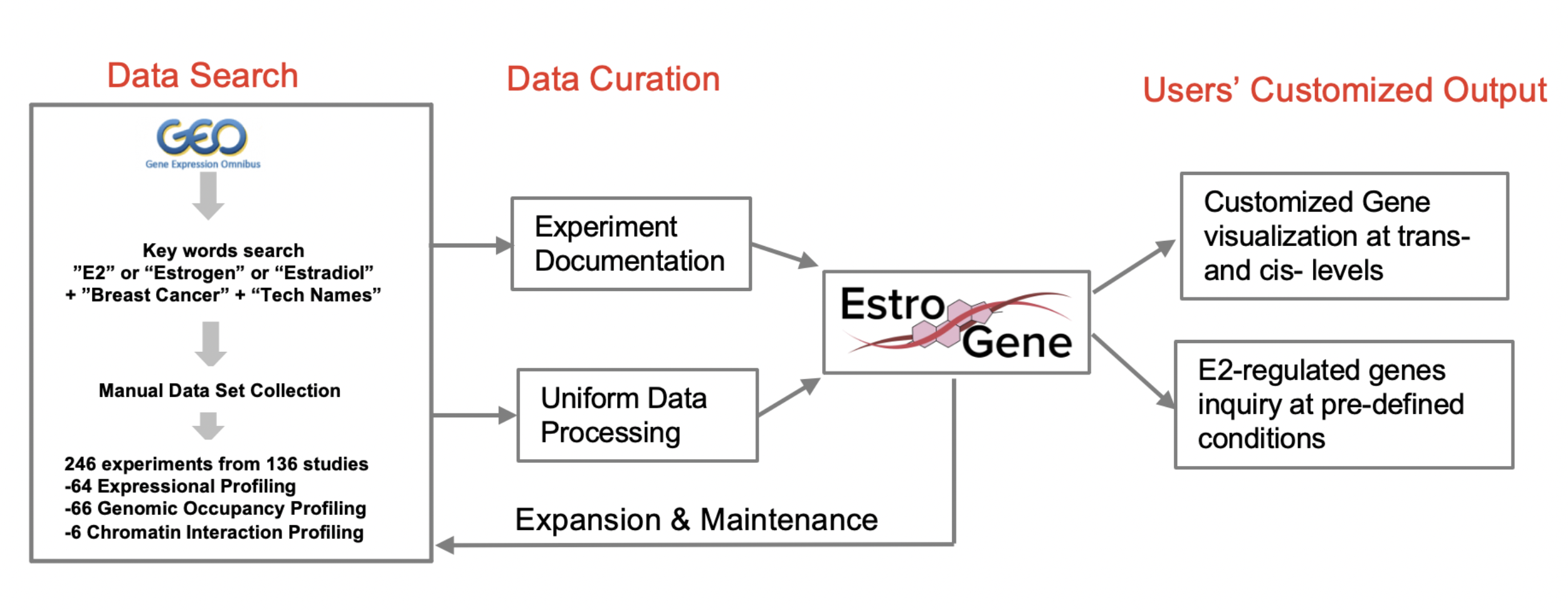
EstroGene database currently curates 136 publicly available data sets from eight distinct NGS technologies, which consists of 246 data points for downstream analysis. All data sets were downloaded from Gene Expression Omnibus and processed under the uniformed pipelines. For all the data sets, we provide metadata inventory with detailed experiment documentations and open for crowd-sourcing. We processed and analyzed all the microarray, RNA-seq and ChIP-seq data in this beta version.
| Data Type | Technique | Dataset curated | Individual Data Points |
|---|---|---|---|
| Expressional Profiling | RNA-seq | 25 | 66 |
| Microarray | 29 | 80 | |
| Genomic Occupancy Profiling | ATAC-seq | 6 | 7 |
| ER ChIP-seq | 62 | 76 | |
| GRO-seq | 10 | 10 | |
| Genomic Interaction Profiling | ER ChIA-PET | 2 | 2 |
| Hi-C/TCC | 5 | 8 | |
| Total | - | 139 | 249 |
Experimental documentation
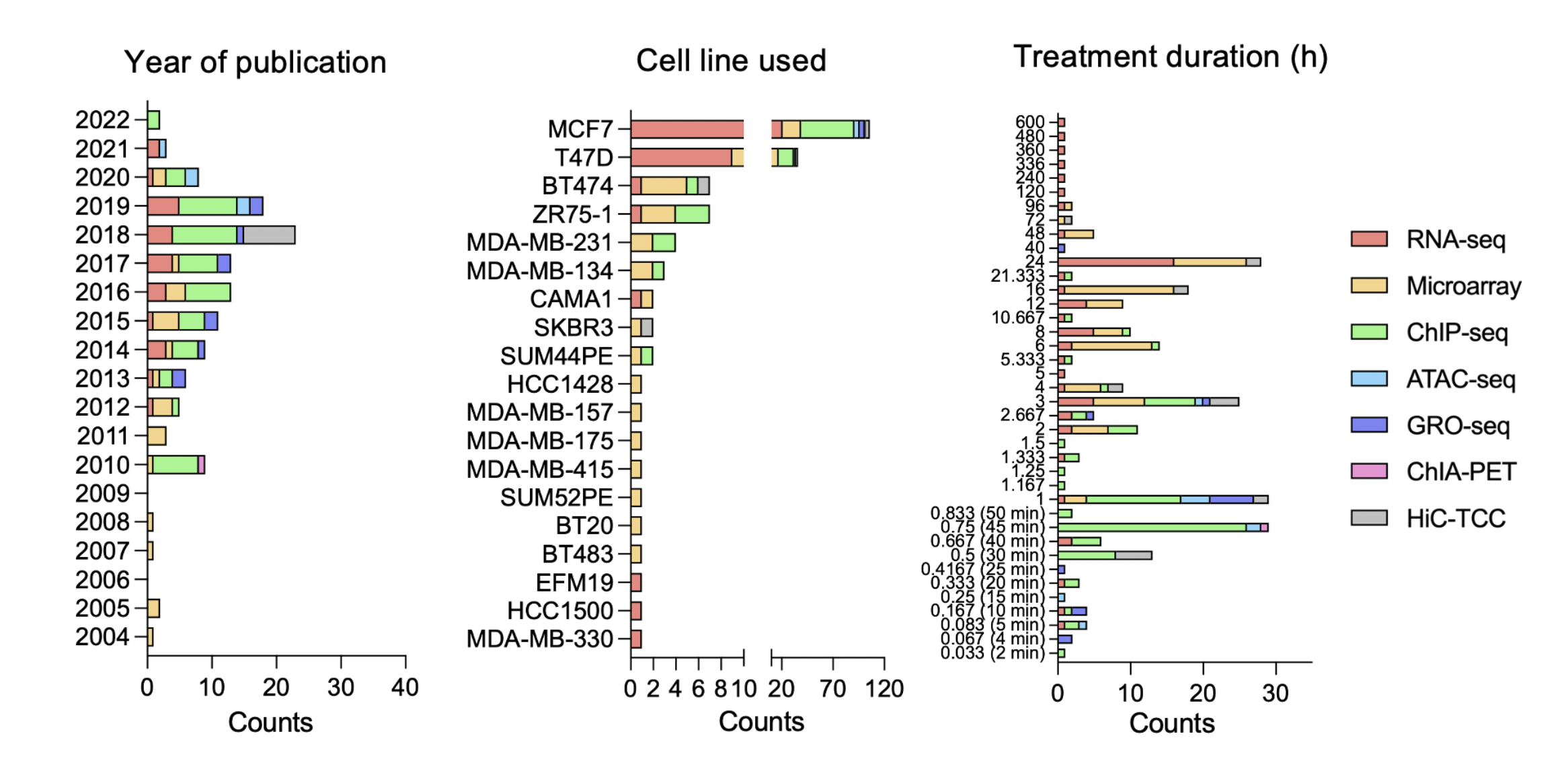
With the rising importance of rigor and reproducibility in scientific research, EstroGene team also closely curated and summarized all the experimental details from each original publication/data portal, as part of the project. Current efforts on RNA-seq/microarray/ChIP-seq data sets analysis revealed two distinct levels of experimental documentations: Essential (Level1) and non-essential (Level2) experimental details to support data analysis and interpretation.
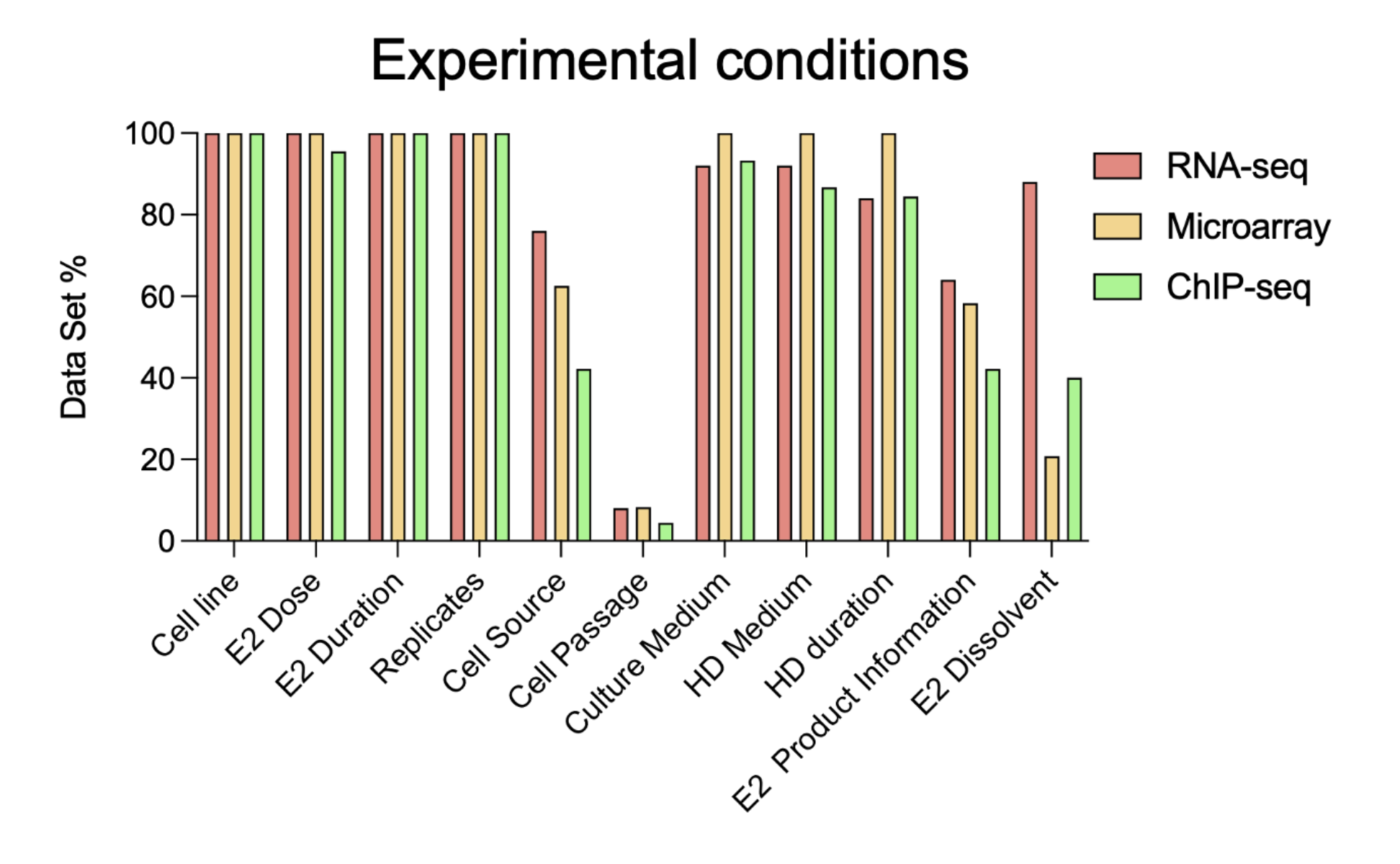
As shown in the figure above, the significant lack of Level2 experimental documentation is uncovered. We would like to take this opportunity to emphasize the importance of reporting all the experimental conditions in NGS data sets to benefit the filed improving rigor and reproducibility.